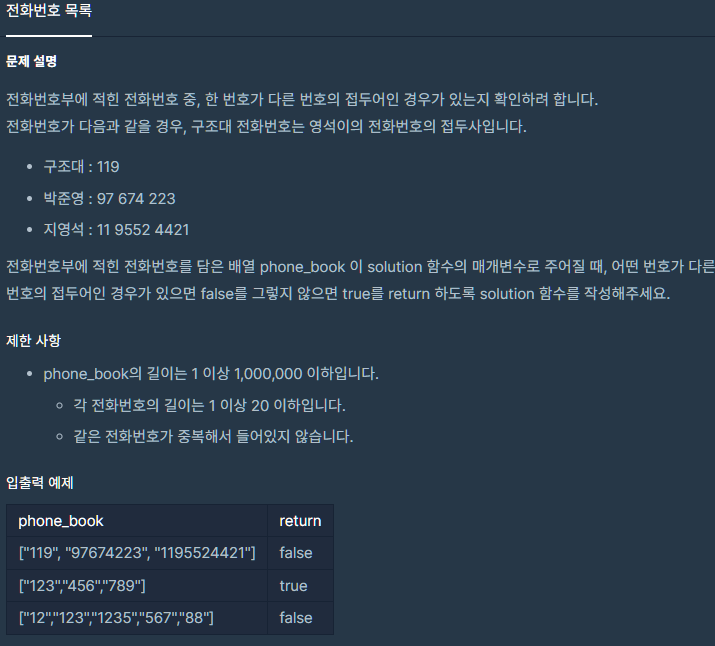
프로그래머스 해시 - 전화번호 목록
1. 문제유형
- hash map
2. 해결과정
- 크게 3가지 풀이방법이 존재했다.
- 2중 for문을 활용하는 방법
- 문자열 내장함수 startswith를 사용한 방법
- hash를 활용한 방법
- 결론적으로 1번 방법은 시간복잡도가 O(N^2)이므로 효율성 문제를 통과할 수 없다.
- 따라서 2번과 3번을 활용한 풀이가 가능하다.
3. 소스코드
def solution1(phone_book):
answer = True
phone_book = sorted(phone_book, key=len)
for n1 in phone_book:
for n2 in phone_book:
if n1 == n2[:len(n1)] and n1 != n2:
answer = False
return answer
return answer
def solution2(phone_book):
phone_book.sort()
for p1, p2 in zip(phone_book, phone_book[1:]):
if p2.startswith(p1):
return False
return True
from collections import defaultdict
def solution3(phone_book):
hash_map = defaultdict(int)
for p in phone_book:
hash_map[p] += 1
for phone_number in phone_book:
tmp = ''
for t in phone_number:
tmp += t
if tmp in hash_map.keys() and tmp != phone_number:
return False
return True4. Dictionary vs List
- 3번째 풀이에서 tmp를 hash_map에 존재하는 지 탐색하는 과정에서 의문이 생겼다.
- 어쨋든 저장된 개수는 최대 100만개인데, List에서는 시간초과가 났다.
- https://www.jessicayung.com/python-lists-vs-dictionaries-the-space-time-tradeoff/
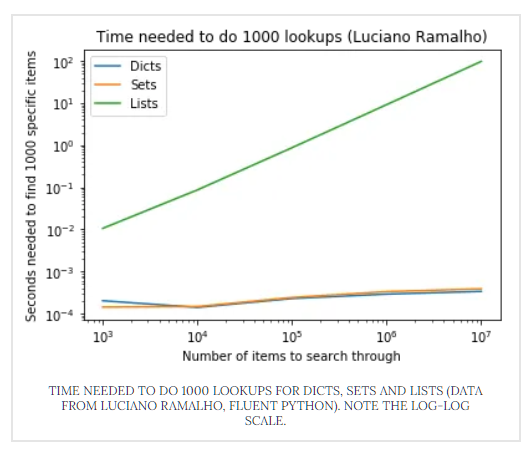
- Then why not always use dictionaries? Looking up entries in Python dictionaries is fast, but dicts use a lot of memory.* This is a classic example of a space-time tradeoff. Update: From Python 3.6, dictionaries don’t use that much space. So it’s not even a space-time tradeoff any more.) Why is looking up entries in a dictionary so much faster? It’s because of the way Python implements dictionaries using hash tables. Dictionaries are Python’s built-in mapping type and so have also been highly optimised. Sets are implemented in a similar way.
- 해당 링크의 글을 참고하자면, 기존 딕셔너리는 리스트에 비해 더 빠른 탐색이 가능하나 메모리 공간을 많이 차지하는 문제가 있었다. 따라서 space-time tradeoff 관계에 있었으나, Python 3.6 버전 업데이트 후로는 메모리 사용량도 감소하여 상충관계에서 벗어난 것으로 보인다. Dictionary는 List보다 탐색속도가 빠른 이유는 Hash Table로 구성된 자료구조이기 때문이다.
'알고리즘' 카테고리의 다른 글
| 시뮬레이션 - 13335 트럭 / 14499 주사위굴리기 (0) | 2021.09.06 |
|---|---|
| 프로그래머스 [해시] - 위장 (0) | 2021.09.06 |
| 2606 바이러스, 14502 연구소 - DFS/BFS (0) | 2021.08.25 |
| 백준 - 11977 Angry Cows [이분탐색, 브루트포스] (0) | 2021.08.17 |
| 백준 - 1477 휴게소 세우기 [이분탐색] (0) | 2021.08.15 |