
파이썬은 원래 데이터 분석에 특화된 언어가 아닙니다.
R로 분석하던 것을 파이썬으로 하고 싶은 개발자들이 만든 도구가 Numpy와 Pandas입니다.
데이터분석을 위한 파이썬의 기본 자료구조 딕셔너리, 리스트만으로는 부족했기 때문에,
Pandas에는 데이터프레임, 시리즈라는 자료구조가 추가되었습니다.
1. 데이터 프레임 생성
데이터 프레임을 만드는 방법은 여러 가지가 있습니다.
일반적으로 배열, 리스트, 딕셔너리로 만들 수 있습니다.
1.1. 배열로 생성하기
첫 번째는 배열(array)을 이용해서 만드는 방법입니다.
우선 배열 자료구조를 사용하기 위해 numpy를 불러오고, pandas도 import 합니다.
import pandas as pd
import numpy as npsample_array = np.arange(1,6)
sample_array

생성된 배열로 데이터 프레임을 만들겠습니다.
sample_df = pd.DataFrame({
'col1' : sample_array,
'col2' : sample_array*2,
'col3' : ["A","B","C","D","E"]
})
print(sample_df)
1.2. 리스트로 생성하기
데이터프레임은 리스트로도 만들 수 있습니다.
df = pd.DataFrame([[80,90,100,70],[70,80,90,100]],
index=['달리기','점프'],
columns=['모모','츄츄','디디','루루'])
df
1.3. 딕셔너리로 생성하기
이번엔 딕셔너리로 만들어 보겠습니다.
딕셔너리는 key와 그에 대응하는 value로 이루어진 자료구조입니다.
data = {'score1' : [91,94,97,100], 'score2' : [100, 97, 94, 91]}
data
data = pd.DataFrame(data, index=['a','b','c','d'])
data
2. 데이터프레임 병합
데이터 프레임을 합치는 방법은 4가지가 있습니다.
1. pd.concat()
2. df.append()
3. pd.merge()
4. df.join()
먼저 pd.concat 함수에 대해 먼저 알아보겠습니다.
2.1. pd.concat()
데이터 프레임을 두 개 생성하고, concat함수를 사용해 세로로 붙여보겠습니다.
df_1 = pd.DataFrame({
'모모' : np.array([90,80,70]),
'츄츄' : np.array([70,80,90])
},index=['먹기','달리기','점프'])
df_2 = pd.DataFrame({
'모모' : np.array([90,100,60]),
'츄츄' : np.array([80,90,95])
}, index=['그루밍','깨물기','냥냥펀치'])


# concat을 사용해 세로로 병합
pd.concat([df_1,df_2])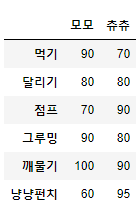
다음은 가로로 합쳐보겠습니다. 가로로 concatenate할 때는 주의해야합니다.
행과 열중에 보통 행연산에 대해서는 관대한 편이지만, 열에 관해서는 조심할 필요가 있습니다.
예를 들어 탑승객 데이터가 있다고 할 때, 행 1줄이 변경되는 것은 1명의 정보에 영향을 미칩니다.
하지만 열 하나가 삭제되거나 잘못 변경될 경우 모든 탑승객의 정보에 대해 영향을 미치기 때문입니다.
concat함수의 default 옵션이 세로(axis=0)로 되어있는 이유이기도 합니다.
그럼 이번엔 옵션을 추가해서 세로가 아닌 가로로 붙여보도록 하겠습니다.
pd.concat([result, df_result], axis=1)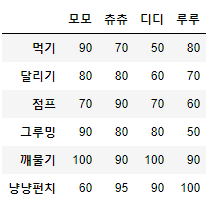
이렇게 해줄수도 있지만, 소개한 두 번째 방법인 append함수를 이용해서 병합할 수도 있습니다.
2.2. df.append()
df_1.append(df_2)
2.3. pd.merge()
merge함수의 경우 Concat과 달리, 중복된 행은 자동으로 처리합니다.
반면 concat의 경우 병합시 그대로 합쳐진다는 점이 차이가 있습니다.
df_11 = pd.DataFrame({
'col1' : np.array([90,80,70]),
'col2' : np.array([70,80,90])
})
df_22 = pd.DataFrame({
'col1' : np.array([90,100,60]),
'col2' : np.array([70,90,95])
})

pd.concat([df_11, df_22])
pd.merge(df_11, df_22, how="outer")
이번엔 on 파라미터를 사용해 Key를 기준으로 Merge 해보도록 하겠습니다.
# 데이터 프레임 생성
left = pd.DataFrame({
'Key': ['키1','키2','키3','키4'],
'A': ['A0','A1','A2','A3'],
'B': ['B0','B1','B2','B3']
})
right = pd.DataFrame({
'Key': ['키1','키2','키3','키4'],
'C': ['C0','C1','C2','C3'],
'D': ['D0','D1','D2','D3']
})

# Key를 중심으로 left, right 데이터프레임 병합
result = pd.merge(left, right, on='Key')
result
2.4. df.join()
Joint 방식에 대해서는 파라미터로 how를 사용해보도록 하겠습니다.
how에 left를 주느냐, right를 주느냐에 따라 병합 결과가 달라집니다.
왼쪽 프레임과 오른쪽 프레임 중 어디를 기준으로 하느냐의 차이입니다.
예시를 보겠습니다.
left = pd.DataFrame({
'A':['A0','A1','A2'],
'B':['B0','B1','B2']
}, index=['K0','K1','K2'])
right = pd.DataFrame({
'C':['C0','C2','C3'],
'D':['D0','D2','D3']
}, index=['K0','K2','K3'])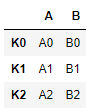

# 왼쪽(left) 데이터 프레임 기준으로 병합
result = left.join(right, how='left')
result
# 오른쪽(right) 데이터 프레임 기준으로 병합
result = left.join(right, how='right')
result
3. 데이터프레임 열 추출하기
이번엔 예시로 된 샘플 데이터 프레임을 생성한 뒤, 열에 해당하는 값들을 추출해 보겠습니다.
sample_df = pd.DataFrame({
'col1' : np.array([1,2,3,4,5]),
'col2' : np.array([2,4,6,8,10]),
'col3' : np.array(["A","B","C","D","E"])
})
열 이름을 지정해서 호출하려면 DataFrame.col_name 형식으로 점(.)을 사용합니다.
sample_df.col2
대괄호를 이용해서도 호출할 수 있습니다.
sample_df["col2"]
여러 개의 컬럼을 호출하고 싶을 땐 대괄호를 한 번 더 사용합니다.
sample_df[["col1","col2"]]
4. loc함수와 iloc함수 사용하기
이번엔 loc과 iloc함수를 이용해 데이터를 더 디테일한 방법으로 추출해보겠습니다.
예시로 데이터 프레임을 하나 만들겠습니다.
df = pd.DataFrame(
[[90,80,70, 40, 90, 50], [70,80,100, 90, 40, 70], [50, 100, 80, 30, 60, 100]],
index=['모모', '츄츄', '티티']
,columns=['먹기','달리기','점프','그루밍','깨물기','냥냥펀치'])
df
4.1. loc함수
위에서 생성한 샘플 데이터 프레임입니다.

우선 인덱스를 하나만 줄 경우, 해당 인덱스에 대한 행을 가져옵니다.
df.loc['모모']
이번엔 리스트 형태로 인덱스를 2개 줘 보도록 하겠습니다.
df.loc[['모모', '츄츄']]
또한, loc 안에 조건식을 넣을 수도 있습니다.
해당 조건을 만족하는 데이터만 뽑아낼 수 있는 것이죠. 🙂
# 그루밍 능력이 50이 넘는 고양이만 추출
df.loc[df['그루밍']> 50]
# 그루밍 능력이 50보다 작은 고양이만 추출
df.loc[df['그루밍']<50]
위에서는 그루밍 능력이 50 이상인 행의 모든 컬럼값을 추출했지만
특정 Column값만 추출하는 것도 가능합니다.
# 그루밍 능력이 50보다 작은 고양이들의 '냥냥펀치' Column만 추출
df.loc[df['그루밍']< 50, '냥냥펀치']
4.2. iloc 함수
마지막으로 iloc 함수입니다.
loc과 iloc의 가장 큰 차이는 label 기반 인덱싱이냐, integer 기반 인덱싱이냐입니다.
쉽게 말해 iloc 함수는 숫자를 기반으로 인덱싱을 합니다.
iloc의 i도 integer-location의 줄임말입니다.
예를 들기 위해 위의 데이터프레임을 다시 사용하겠습니다.
df = pd.DataFrame(
[[90,80,70, 40, 90, 50], [70,80,100, 90, 40, 70], [50, 100, 80, 30, 60, 100]],
index=['모모', '츄츄', '티티']
,columns=['먹기','달리기','점프','그루밍','깨물기','냥냥펀치'])
df
iloc 함수를 이용해서 우선 열만 추출해 보겠습니다.
# 0번째 column은 '먹기'입니다.
df.iloc[:,0]
여러 개 가져오는 것도 가능합니다.
# 0번째, 1번째 column은 먹기, 달리기 입니다.
df.iloc[:,[0,1]]
loc과 동일하게 콜론(:)을 이용해서도 인덱싱이 가능합니다.
# 1번째, 2번째, 3번째 컬럼 추출 : 달리기, 점프, 그루밍
df.iloc[:,1:4]
같은 방식으로 행에 대해서도 추출할 수 있는데요.
똑같은 방식으로 진행해 보겠습니다. 우선 행 1개만 추출합니다.
# 0번째 행은 '모모'입니다.
df.iloc[0]
행 2개를 추출해 보겠습니다.
# 0번째, 1번째 행은 '모모', '츄츄'입니다.
df.iloc[[0,1],:]
같은 방식으로 콜론(:)을 사용해서 인덱싱 해 보겠습니다.
# 1번째, 2번째 행은 '츄츄', '티티'입니다.
df.iloc[1:3, :]
이상으로 Pandas로 데이터프레임을 생성하는 방법과 병합하는 방법,
그리고 loc, iloc 함수를 이용해 데이터를 추출하는 방법에 대해 알아보았습니다. 🙂
'데이터사이언스' 카테고리의 다른 글
| 과적합(Overfitting) 방지하기 (0) | 2021.03.08 |
|---|---|
| 활성함수의 역할과 종류 이해하기 (0) | 2021.03.03 |
| 구글 플레이 스토어 - 리뷰 데이터 크롤링하기 (21) | 2021.01.14 |
| 외모지상주의 - 베스트 댓글 크롤링하기 (6) | 2021.01.12 |
| Pickle과 Write 차이점 + With ... as 구문 (0) | 2020.12.29 |