스타듀밸리 어플 리뷰 크롤링

인디 게임인 스타듀밸리에 대한 리뷰를 크롤링 해보았습니다.
저도 구매해서 플레이 해봤는데 굉장히 재미있습니다.
다들 큰 기대 없이 시작하지만 한 번 빠지면 몇 시간 뚝딱입니다.
Golden Joystick 혁신상을 비롯해 여러 곳에서 상을 받은 게임답습니다.
play.google.com/store/apps/details?id=com.chucklefish.stardewvalley&hl=ko&gl=US
스타듀 밸리 Stardew Valley - Google Play 앱
ConcernedApe의 대인기 농장 RPG가 모바일 버전으로 찾아옵니다! 각종 수상 경력에 빛나는 농장 RPG에서 농촌으로 떠나 새로운 삶을 경험해 보세요! 50시간 이상의 즐길거리를 제공합니다. 새로운 엔
play.google.com
1. 데이터 크롤링
크롤링 할 데이터는 어플 이름, 아이디, 리뷰, 별점, 날짜로 총 5가지입니다.
우선 라이브러리를 임포트하겠습니다.
import pandas as pd
import time
from selenium import webdriver
pd.set_option('display.max_rows', 100)
그리고 데이터를 저장할 데이터프레임도 생성합니다.
data = pd.DataFrame(data=[], columns=['앱이름','아이디','리뷰','별점','날짜'])
Selenium의 webdriver를 사용해 페이지를 띄우도록 하겠습니다.
driver = webdriver.Chrome("chromedriver.exe")
url = 'https://play.google.com/store/apps/details?id=com.chucklefish.stardewvalley&hl=ko&gl=US'
driver.get(url)
스크롤을 내려서 보시면 리뷰가 4개까지 밖에 안보입니다.
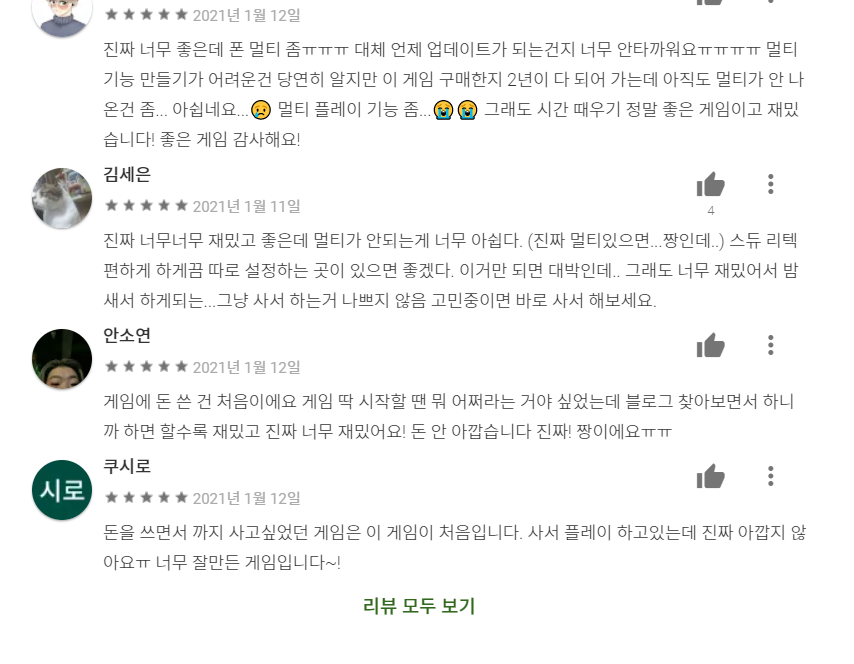
셀레니움을 조작해서 '리뷰 모두 보기'버튼을 클릭하도록 하겠습니다.
driver.find_element_by_xpath('//*[@id="fcxH9b"]/div[4]/c-wiz/div/div[2]/div/div/main/div/div[1]/div[6]/div/span/span').click()
F12개발자 도구에서 '리뷰 모두 보기'에 해당하는 태그의 xpath를 복사 후 붙였습니다.
리뷰는 스크롤을 내릴수록 늘어나므로, 스크롤을 내리는 함수도 만들겠습니다.
# 스크롤 다운
def scroll_down(driver):
driver.execute_script("window.scrollTo(0, 999999999999)")
time.sleep(1)scroll_down(driver)
이제 데이터를 수집할 것입니다.
그런데 리뷰 모두 보기 버튼 클릭 후 바로 수집을 하면 태그를 제대로 인식하지 못하는 문제가 있었습니다.
따라서 driver.get()으로 현재 주소를 다시 새로고침 한 뒤 수집하겠습니다.
driver.get('https://play.google.com/store/apps/details?id=com.chucklefish.stardewvalley&hl=ko&gl=US&showAllReviews=true')
나중엔 함수로 만들어 수집을 자동화 할 것이지만
우선은 어플 이름, 아이디, 리뷰, 별점, 날짜를 각각 1개씩 수집해 보겠습니다.
# 어플 이름 수집
app_name = driver.find_element_by_css_selector('.AHFaub')
app_name.text
# 유저 이름 수집
user_names = driver.find_elements_by_css_selector('.X43Kjb')
user_names[0].text
# 리뷰 수집
reviews = driver.find_elements_by_css_selector('.UD7Dzf')
reviews[0].text
역시 멀티가 안되는 건 참 아쉬운 부분입니다. 😢
# 별점 수집
star_grades = driver.find_elements_by_xpath('//div[@class="pf5lIe"]/div[@role="img"]')
star_grades[0].get_attribute("aria-label")
여기서 별점을 수집할 땐 다른 데이터와 다른 방식으로 접근해야 했습니다.

나머지 데이터들은 수집하고자 하는 데이터가 텍스트였습니다.
하지만 별점은 aria-label이라는 '속성값' 입니다.
따라서 xpath로 순차적으로 접근한 뒤, get_attribute()함수를 이용해 크롤링하였습니다.
또한 xpath를 Copy & Paste한 것이 아니라, 직접 작성했습니다.
맨 앞의 //가 현재 노드를 기준으로 라는 점을 빼면 코드는 직관적입니다.
# 날짜 수집
dates = driver.find_elements_by_css_selector('.p2TkOb')
dates[0].text날짜도 마저 수집해 줍니다.

이제 하나의 함수로 구현해서 여러 개의 리뷰를 수집한 뒤 저장하겠습니다.
def crawl(driver, data, k):
# 어플 이름, 아이디, 리뷰, 별점, 날짜 수집
app_name = driver.find_element_by_css_selector('.AHFaub')
user_names = driver.find_elements_by_css_selector('.X43Kjb')
reviews = driver.find_elements_by_css_selector('.UD7Dzf')
star_grades = driver.find_elements_by_xpath('//div[@class="pf5lIe"]/div[@role="img"]')
dates = driver.find_elements_by_css_selector('.p2TkOb')
# k개의 리뷰를 수집합니다.
for i in range(k):
tmp = []
tmp.append(app_name.text)
tmp.append(user_names[i].text)
tmp.append(reviews[i].text)
tmp.append(star_grades[i].get_attribute('aria-label'))
tmp.append(dates[i].text)
# 수집한 1명의 리뷰를 결과 프레임에 추가합니다.
tmp = pd.DataFrame(data=[tmp], columns=data.columns)
data = pd.concat([data,tmp])
print(app_name.text + "앱 리뷰 수집 완료")
return data
해당 함수를 이용해서 평가 리뷰를 200개만 뽑아보겠습니다.
# 스크롤 다운을 한 뒤, 크롤링을 해야 인덱스 에러가 발생하지 않음
scroll_down(driver)
data = crawl(driver,data, 200)# 인덱스 번호를 다시 0부터 리셋합니다.
data.reset_index(inplace=True, drop=True)
data.head()
2. 데이터 전처리
수집한 데이터 중 별점 컬럼은 굳이 문자열로 남겨둘 필요는 없어보입니다.
숫자값만 남기도록 하겠습니다.
# 원본 데이터 카피
tmp = data.copy()
re 라이브러리와 정규표현식을 사용해서 숫자만 뽑아내려고 합니다.
그러기 위해 우선 앞에 별표 5개 부분은 잘라냈습니다.
# 앞의 별표 5점은 생략
tmp['별점'] = tmp['별점'].apply(lambda x: x[5:])
tmp.head(3)
그리고 re 라이브러리를 임포트한 후 정규표현식을 사용하겠습니다.
정규표현식에 대해 간단히 정리하자면
[a-z]는 a부터 z까지의 알파벳 중 하나를 의미합니다.
[0-9]는 0부터 9까지의 숫자 중 하나를 의미합니다.
*은 앞의 문자(숫자, 특수문자 포함)가 0개 이상 등장함을 의미합니다.
+는 앞의 문자(숫자, 특수문자 포함)가 1개 이상 등장함을 의미합니다.
.은 어떤 문자든 1개가 등장함을 의미합니다.
\(역슬래쉬)는 .이 정규표현식의 .이 아니라, 순수한 문자열임을 나타낼 때 표시합니다.
import re
m = re.compile('[0-9][\.0-9]*')
tmp['별점'] = tmp['별점'].apply(lambda x : m.findall(x)[0])따라서 정수형 숫자 1개만 있거나, 4.8 과 같이 소수점으로 계산된 점수를 추출합니다.
tmp.head()
마지막으로 데이터를 저장하겠습니다.
csv파일은 to_csv, excel 파일은 to_excel 함수를 이용하면 됩니다.
파일의 크기가 큰 경우, csv파일은 ,를 기준으로 값을 저장하기 때문에 효율적입니다.
tmp.to_csv('스타듀밸리_리뷰평점.csv', encoding='utf-8')
tmp.to_excel('스타듀밸리_리뷰평점.xlsx')re = pd.read_csv('스타듀밸리_리뷰평점.csv', encoding='utf-8')
re.head()
데이터도 잘 불러와 지네요.
이상으로 구글 플레이 스토어의 리뷰 데이터를 크롤링 해보았습니다. 🎉
'데이터사이언스' 카테고리의 다른 글
| 과적합(Overfitting) 방지하기 (0) | 2021.03.08 |
|---|---|
| 활성함수의 역할과 종류 이해하기 (0) | 2021.03.03 |
| 외모지상주의 - 베스트 댓글 크롤링하기 (6) | 2021.01.12 |
| Pandas - 데이터프레임 생성/병합/추출하기 (4) | 2021.01.08 |
| Pickle과 Write 차이점 + With ... as 구문 (0) | 2020.12.29 |